
Steve has recently conducted webinars for Gurobi about best practices in applied optimization. Following are excerpts from the Q&A sessions.
The Optimization Edge
A Blog for Business Executives and Advanced Analytics Practitioners
Technologies: Data Science, Big Data, Optimization, Machine Learning, Artificial Intelligence, Predictive Analytics, Forecasting
Applications: Operations, Supply Chain, Finance, Health Care, Workforce, Sales and Marketing
March 13, 2024
Posted by:
February 21, 2024
Posted by:
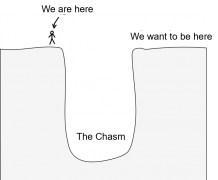
Following are excerpts from Steve's Jan. 25 webinar hosted by Gurobi Optimization.
The AI optimization success lifecycle—from the charter to the harvest—represents a wonderful world. However, today we will get away from the “wonderful” and talk about what really happens in the field. Often, colleagues and I see that a chasm forms between the early win and the scale-up. In the early win, a Proof of Concept (PoC) is in production at a pilot site, but the organization has been unable or unwilling to scale it across the enterprise.
January 17, 2024
Posted by:

Steve recently gave a guest lecture to Professor Shruti Sharma’s introductory class on optimization for graduate students at the NYU Tandon School of Engineering, in the Technology Management and Innovation Department. Following are lightly edited excerpts.
November 14, 2023
Posted by:

What optimization solvers, programming and modeling languages do professors, students and industry practitioners use? Do they align? At the INFORMS Annual Meeting in October in Phoenix, Princeton Consultants asked attendees to see what has changed since 2017, the last time we conducted the survey.
October 9, 2023
Posted by:

Following are lightly edited excerpts from Steve’s recent presentation in a Gurobi Optimization webinar. Watch the recording here.
If optimization is so powerful, why do top executives need convincing to invest in it? Well, they are constantly pitched, by internal colleagues and external advisors, to spend money in many different areas. They learn to say no to anything that isn’t focused on accomplishing their business strategy.
September 1, 2023
Posted by:

I was recently interviewed on “Tech Leaders Unplugged,” a podcast for businesspeople that covers “the latest technology trends and innovations from AI to the blockchain, fintech to health tech.” Watch or listen to the 30-minute interview here. Here are some lightly edited excerpts.
Wade Erickson: A lot of our listeners come from the tech space. We’ve seen quite a frenzy around AI. Can you talk a little bit about the process that’s involved when you’re presented a project—how optimization goes into the design thinking and the evaluation of the current workflows in the application? Where do you insert your background and intellect into that process? How does that show up in the software development teams to insert the new algorithms, and the new models and methods to optimize?
July 13, 2023
Posted by:

Irv was interviewed by Lityx CEO Paul Maiste for the Data Stories podcast. Following are lightly edited excerpts. Listen to the full conversation here.
June 9, 2023
Posted by:

In manufacturing, there is often a competition between mass production and custom artisanship: produce vast quantities of product at low cost or produce it in tiny amounts at high fit. Can you achieve low unit cost and scalability from mass production, and the high necessary fit for each consumer from custom artisanship?
May 4, 2023
Posted by:

Following is an excerpt from Steve’s 3/31 presentation to transportation and logistics executives, hosted by Stifel’s equity research group.
There are rail executives who talk about disruption because, starting around 2011, the railroads started to lose massive market share to trucking. The gap is presently widening. If rail transportation costs less and improves supply chain resiliency versus a truck-only strategy, and if it is more energy efficient and emits lower greenhouse gases than trucking does, why is it losing share?
April 7, 2023
Posted by:

On April 6, Steve Sashihara returned to Road Dog Trucking Radio to discuss trucking and emerging technology. Following are excerpts of his conversation with host Mark Willis.