
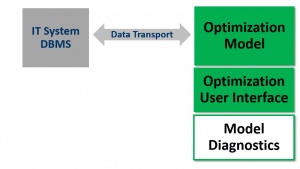
The optimization solutions that we design and deliver typically consist of these components: an information technology (IT) system that consists of a database management system (DBMS), a data transport/communication layer to an optimization model, an optimization user interface, and some model diagnostics.
The IT system and the DBMS serve as the system of record and correspond to an execution system. For example, if you are dispatching trucks and trying to optimize the deliveries of trucks, there will be a system tracking all the orders, trucks, drivers, and their locations. In supply chain, it is typically an ERP system. There is often persistent storage. It is the permanent system of record, which doesn’t go away.
This execution system is essentially how the company runs its business. It is typically a transaction-based system with user interfaces that allow people to add and edit, delete and change other data elements. Those data elements are the data that will be important for optimization.
The data transport is typically something we build. It is bi-directional, allowing the data to be pulled from the IT system into the optimization, and then push solutions out. We often use an intermediate database (referred to as a "staging" database) to record the transactions. The intermediate database is valuable because it gives you an audit and debug capability, lets you see the data pulled in and the solutions pushed out, allows you to replicate, and gives you logging capability.
We typically build this in a services‑oriented architecture so there are loosely coupled generic transactions. We try to design it for maximum flexibility. If the IT system should change, then the new IT system simply has to comply with the same transactions, in terms of being able to really provide the data in the format we specified, and to receive the solutions in the format we specified. We use a lot more of JSON because it is very human readable and makes it easy to understand. Ten years ago, we were using XML. Before that, we used CSV files. JSON is very easy to use within a services‑oriented architecture.
Data translation is very important. We massage the data to make it appropriate for optimization, and we validate that the data satisfies the assumptions that our model needs. We don’t assume that the data that comes from the IT system meets our optimization requirements.
The model includes of course the objective function, different types of rules and constraints, and algorithms. The algorithms can be as simple as calling an embedded mathematical optimization solver such as IBM ILOG CPLEX or Gurobi, or can be more advanced, where we have designed an algorithm that repetitively uses the solver in order to get a final solution.
The optimization model has to maintain state. Sometimes you want to solve a problem, and then you want to be able to start from the previous solution and start a new optimization. That's what we mean by “state.” It also has a log to indicate what is happening during the solution process, such as a solver log, and it had can handle different commands and notifications such as start a new solve, or start from the previous solution. It can also do notifications of things that might be going wrong, such as the problem could be infeasible, you could have a timeout, you could run out of memory, etc.
Our team builds the optimization user interface, which is not necessarily the user interface for the deployed system, though often it does become that. This user interface is browser‑based, has a rich client, or sometimes before a rich client, you could end up using something like a system that facilitates model development, but it communicates with that model on a server. This interface displays some of the model’s internals, which may not be useful for the end users of the optimization system, but the interface lets us know that the data is making sense and the optimization is doing what it needs to do. It helps users visualize what the optimization is doing, but it is not necessarily something that they are going to use in the day-to-day deployed system.
Finally, there are model diagnostics. Because we keep track of the inputs and the recommendations of the solutions, we can replay them and diagnose any issues. We keep track of the state by doing a snapshot, and we sometimes keep track of the user interface log to see what parts the users are using of the user interface that we built. This helps us understand which parts are no longer necessary or which parts are creating confusion that we may need to modify in the actual user interface.
We can help you make sure that your optimization systems are following these tried and true design principles. Contact us to learn more.